Going up river
libwww-perl - CPAN Pull Request Challenge, April 2017
Each month the pull request challenge has presented a very different view onto CPAN. We’ve had small modules and large modules, pure perl and XS. This month we had libwww-perl. Most people have used it when they use LWP::UserAgent. In Neil Bowers talks of the river of cpan it’s pretty far upstream as far as modules go. Breaking it could result in some serious real world software breakage. Of course that common use also means that actually the core of it is pretty robust as it’s used so often most of the common bugs were solved years ago. It’s also pure Perl which was a relief after dealing with the XS code of the our previous month’s challenge.

Despite the fact that this module is well used there is a pretty large bug list. In theory that’s a good thing for a pull request challenge as it allows you plenty of choices for things to work on. The problem is that if it’s a fairly commonly used piece of software most of the bugs will be sorted. That means that those left are probably awkward for various reasons. Some because they aren’t really bugs, some because they are really esoteric edge cases, but generally they are tricky for some reason.
Since there were so many issues on the list in the run up to our traditional ‘pull request evening’ we took a look at the bug list to try to figure out what would be worth doing. In doing so we found a few that were invalid (#131, #214, #219, #223, #227, #232) either because they had already been fixed, or they were a duplicate, or they might have been illustrating a problem in another module that made use of this one.
In truth I suspect there may be a few more invalid bugs, that can be simply closed. There are a few relating to SSL for example that are quite likely either closable because they are no longer in scope, or things have moved on sufficiently that they are no longer true. The SSL is one of the areas that illustrates the change in the module over time. Originally a lot of code was bundled into the one module, and over time it was separated out into other modules. A lot of the SSL modules are tied to underlying operating system packages too so issues with SSL/TLS communication are quite often down to factors outside of the modules direct control. I’ve seen Debian Squeeze boxes become defunct simply because they can’t easily install a new enough version of openssl to support the newer TLSs and lots of websites are now starting to ensure that they only allow communication with the newer versions to prevent security problems.
Then there are bugs that may be technically feasible to fix, but don’t seem to make sense when you look at the standards as specified in the RFCs. There are two issues (#182, #224) relating to the PUT method that should probably be easy enough to implement, but when you read the original HTTP RFCs it’s hard to justify doing so. I wonder how many people have wondered about that too. Of course it’s perfectly possible to come across servers that support use of all the major methods in pretty identical ways, so this is a real use case, it’s just one where I image others have faltered at too.
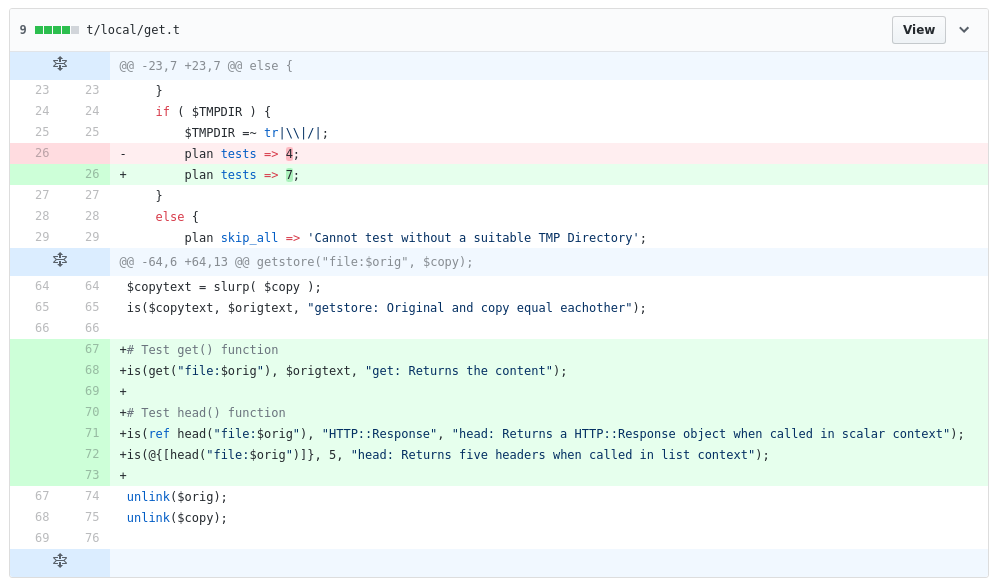
We got a couple of pull requests off early (#252 and #253) which ensured we had done the challenge! These increased the code coverage of the module a little bit as they are using coveralls and travis to ensure the module is tested early and often.

Then there were a couple relating to Digest authentication. This turned out to be awkward because Digest authentication isn’t really used that frequently. In fact after writing the code and tests we found that trying to do real world testing was rather challenging. The first one, attempting to fix the digest calculation for the ‘auth-int’ challenge went late into the night and in one of those ‘let’s get it out’ moments it was pushed broken as part of the test that actually demonstrated it wasn’t working was removed in order to get the tests passing. Luckily the coveralls caught that as a code coverage reduction and looking at the coverage demonstrated how the precise bit of code that should have been tested wasn’t being run at all. That made it easy enough to fix the code and verify that we had at least fixed our tests. The big problem was then trying to test it with a real world server. None of the major web servers (like Apache/nginx/IIS) appear to have implemented that particular facet of digest auth. That one still really requires some real world testing. It looks like webrick might support that option when we can find some more time to try setting up a server with the correct options.
Having been deep in the auth code we then worked on another issue relating to multiple authentication headers being sent when a request is made. This seemed trivial and there were proposed patches for it. In practice when testing this turned out to be tricky too. LWP::UserAgent caches the credentials in the user agent and in the request itself. That means that if you reuse the same request object in theory it should be quick to authenticate as it won’t make a request without the correct auth header on it. The problem is that this requires some detection of when the UA has had its credentials changed. The request can’t always simply try again if it has failed auth lest it end up in an infinite loop constantly retrying when it has no hope of success. The request has enough state to be awkward, but not enough to be useful in some respects.
I do wonder whether that was a worthwhile problem or more of an artificial one created by the testing. Most uses probably instantiate a new UserAgent or request whenever they do things like changing credentials.
This too turned out to be quite tricky to do real world testing against. Such complex auth options again weren’t supported by the major web servers. Luckily the original reporter of the bug was able to verify that the fix worked on their setup.
Working on libwww-perl has been really illuminating as it is a large, very popular and important module. Although intimidating at first, we soon discovered that even here there is “low hanging fruit” that we could find and contribute with. For our development team we think it was a good experience as it helped us conquer the fear factor involved in touching important code. It is something that we can translate directly into our day to day development when dealing with parts of our codebase that are important to the business.
P.S. Did we mention we are hiring developers in both our Fleet and London offices?